Async Processing
This page covers the Async Processor: its benefits, its limitations, how to use it, and how to tune it. The Async Processor is available with Responsive client v0.27.0 onward.
Why use the Async Processor
Async processing allows Kafka Streams applications to concurrently process records within a single task, thus changing the upper limit of parallelization from the level of a Kafka partition to the level of a record key.
It works by giving each StreamThread a dedicated thread pool which it uses to process the records passing through an async processor. Records of the same key are still processed in order and all the same consistency and correctness guarantees of Kafka Streams are maintained, including exactly-once semantics.
The Async Processor was built to shine when processors include a long-running step such as remote state store requests or generic RPCs. The main problem with remote calls during processing in Kafka Streams is that they are executed serially per StreamThread. Thus the total latency of a batch of messages processed by a StreamThread is the sum of the latency of each remote call made while processing that batch. The high cumulative latency can have a crushing effect on throughput.
The classic solution for achieving high throughput when you are bottlenecked by network latency is to increase the parallelism of the calls to the target system, which is exactly what the async processor does for Kafka Streams.
This makes the Async Processor the perfect tool to complement Responsive state stores: you no longer need to sacrifice performance in order to gain the availability and elasticity benefits of remote storage with Kafka Streams!
Expected Performance Gains
As with all real-world systems, performance depends heavily on the specific use case and parameters. However, in all of our experiments, async processing showed a significant improvement over regular Kafka Streams when a topology includes a processor which makes a remote or long-blocking call.
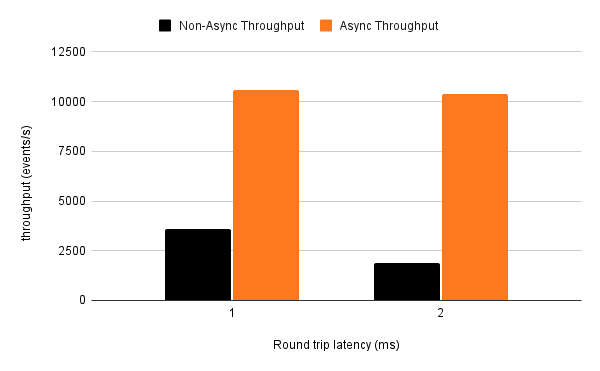
To give an idea of the benefits of using the async processor when your topology includes higher latency external calls, we ran a test that injected a variable latency in our remote storage client while running a simple application that deduplicates events over a window. A couple of things stand out from the results above:
- The greater the remote latency, the bigger the impact of async processing. At 2 ms round trip latency, throughput improves by 5.5x. At 1 ms round trip latency, throughput improves by 3x.
- The throughput with async processing enabled is stable even with varying remote latency. The processor was ultimately bottlenecked by the resources available on the client side!
The async processor makes high round trip network latency a non-factor in achieving high throughput. However, using the async processor will generally place more load on the remote system, which in turn may get saturated, which in turn will drive its latencies, which will mean the throughput gains of the async processor will be below the theoretical maximum.
So make sure to load test with your remote system and tune the async processor accordingly.
Enabling async processing
Turning async processing on (or off!) is quick and easy. All it requires is one line of code and one config and you’re good to go! Make sure to check out the “Limitations” section for what is covered by the current version and what will be coming in a future release.
1. Select and update your existing Processor
Wrap the supplier for the processor you wish to enable async processing for in the appropriate wrapper class:
- For a
.process()with aProcessorSupplier, useAsyncProcessorSupplier#createAsyncProcessorSupplier - For a
.processValues()with aFixedKeyProcessorSupplier, useAsyncFixedKeyProcessorSupplier#createAsyncProcessorSupplier
Example:
// Before
kstream.processValues(
new MyStatefulProcessorSupplier<>(),
Named.as("RegularProcessor"),
STORE_NAME);
// After
kstream.processValues(
createAsyncProcessorSupplier(new MyStatefulProcessorSupplier<>()),
Named.as("AsyncProcessor"),
STORE_NAME);
// note: the Named.as was modified to highlight the example,
// changing the processor name is not required to enable async processing
2. Configure the thread pool
Configure the thread pool size by setting the ResponsiveConfig responsive.async.thread.pool.size to a positive integer. Something like 10 is a good place to start, but make sure to check out the tuning section below for a more detailed discussion of how to tune and configure the Responsive Async Processor.
3. Ensure that you implement the Processor#stores method
Note that the async processing framework requires a stateful processor to connect its StateStores by implementing the ProcessorSupplier#stores method. Please verify that your processor supplier implements this method before passing it into the async wrapper, or switch to this method of connecting state stores if it does not.
You will know if this is not set up correctly by an immediate UnsupportedOperationException upon startup.
Also, while non-Responsive state stores (eg RocksDB) are fully supported for use within an async processor, you must at least use the Responsive StoreBuilder to plug those state stores in.
Make sure that the StoreBuilders being returned from your ProcessorSupplier#stores (if any) use the ResponsiveStores version of the StoreBuilder rather than the basic Stores API.
Tuning the AsyncProcessor
Several new configs have been introduced as part of the async processing feature, but the framework also interacts with several existing Streams and client configs. See the advice below for our thoughts on the best possible setup to make the most of async processing for your application.
Eventually, the Responsive Controller will automatically tune the async processor for you, but if you have questions hop on to our discord and ask us!
Summary
Here is a summary of the relevant configs. More details on each are provided below.
| Config | How to think about it |
|---|---|
commit.interval.ms | The semantics of the commit interval don't change when using the async processor, but a low value will mean you get less of a benefit from using the async processing. |
num.stream.threads | If you have already set the this value, leave it unchanged. If you have not set it, the rule of thumb is to have have twice the number of stream threads as the number of cores on the machine your application is running on. |
responsive.async.thread.pool.size | The size of the async thread pool. There will be one async thread pool per stream thread, so the actual number of async threads on a node will be num.stream.threads x responsive.async.thread.pool.size. We describe why this shouldn't cause a problem in most cases below. |
commit.interval.ms
Although we always advise increasing the commit interval for EOS applications, it is especially advisable to do so when enabling the async processing framework if you want to maximize its potential. If your application has only a few subtopologies (one or two), you can probably bump up the commit.interval.ms to 30s (which is the default for at-least-once-semantics). If your application has a larger number of subtopologies, the end-to-end latency will accrue across them, so it may be good to divide the 30s recommendation by a factor of the subtopology count. Of course you should always make sure to leave room for your end-to-end latency requirements.
When increasing the commit interval, you should always increase the transaction.timeout.ms producer config accordingly. We recommend simply setting this to 15s greater than the value of your chosen commit interval.
num.stream.threads
While an async processor will farm most of the processing work out to its async thread pool, the StreamThread still plays a vital role in moving records through the subtopology and issuing writes. It’s important that you still configure the node with an appropriate number of StreamThreads, most likely the same number that you would have used before enabling async processing. There will be more threads created in total, but keep in mind that the async threads will typically be spending most of their time waiting on the long RPC calls and not soaking up cpu cycles.
Our advice: don’t touch the num.stream.threads config, except to make sure it’s set appropriately to begin with!
responsive.async.thread.pool.size
One of the most important of the new configs is of course the responsive.async.thread.pool.size. Note that this value represents the number of async threads per StreamThread, so the actual number of async threads that will be created is equal to the responsive.async.thread.pool.size x num.stream.threads. As always, the best way to choose a value for something like this is to start with an educated guess and then from there, experiment with your specific setup to find what works best for you.
The rules for selecting a good async thread pool size are a bit different from the rule of thumb for selecting the num.stream.threads (which is usually one StreamThread per core). As discussed above, many of the async threads will spend their time waiting on a blocking call, as is their job, so you’ll want to have many more async threads than cores. Try to configure the thread pool size to be roughly 10 times the number of cores and experiment from there. The sensitivity of an app to the number of async threads is also dependent on the latency of any blocking calls — the longer they spend waiting, the more threads you’ll want to run in parallel.
Limitations
The async processing framework is still under development and has a few limitations at the moment. All of the current restrictions will be lifted in the future as the feature expands to cover more use cases.
- Must be used with the PAPI — this includes both regular and fixed-key processors, and will work whether it is a “pure” PAPI application or a mix-in PAPI processor that uses the
.processor.processValuesDSL operator. Generic DSL operators besides.processand.processValuesare not supported at this time. - Async processing is only compatible with Responsive applications. Some of the async processing functionality is intertwined with the Responsive application framework, such as the thread pool management and configuration. This will be decoupled in the future so please reach out to us if you would like to try the async processing framework for a non-Responsive application.