Quickstart
This guide demonstrates how to get a minimal Responsive environment set up and running. The example use case implements the open source Kafka Streams Demo Application on the Responsive platform.
After completing this quickstart, you will have:
- Deployed an open source
KafkaStreamsapplication on a local KinD cluster - Migrated the code to
ResponsiveKafkaStreams - Deployed the Responsive Operator
- Scaled your application by means of an autoscaling policy
Setup
Begin by cloning the Responsive examples repository:
git clone https://github.com/responsivedev/examples.git
cd examples
The KafkaStreams code is in the streams-app module, and should look familiar if you have
ever implemented "Word Count" in Kafka Streams:
static Topology topology() {
final StreamsBuilder builder = new StreamsBuilder();
...
final KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count(Materialized.as(Stores.persistentKeyValueStore("word-counts")));
// Store the running counts as a changelog stream to the output topic.
wordCounts
.toStream()
.to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
return builder.build();
}
Build & Deploy
Build a docker image containing this application, and use our script to get setup with a KinD cluster containing a Kafka Broker, a data generator and a deployment of the Word Count application.
./gradlew :streams-app:jibDockerBuild
bash ./kind/bootstrap.sh
Setup Responsive Cloud
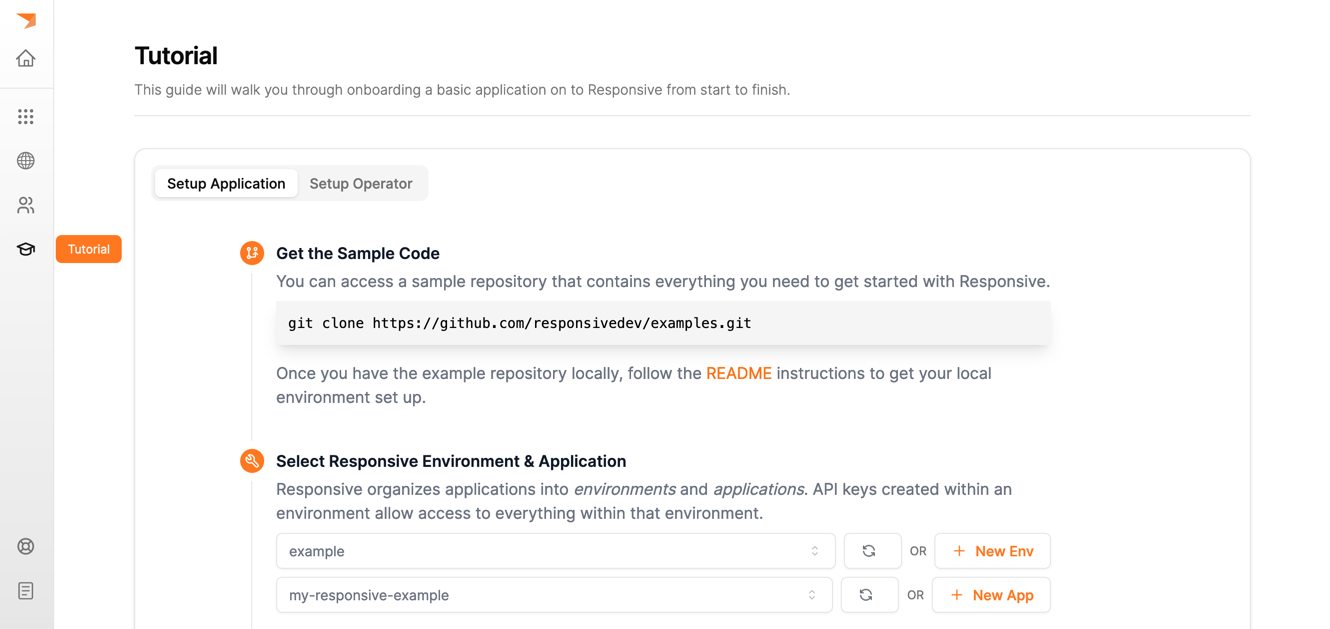
- Log in or sign up to Responsive Cloud and navigate to the Tutorial page (it's the graduation hat on the left sidebar).
- Follow the instructions to create an environment named
exampleand an application with the idmy-responsive-example. - Provision a self-serve storage cluster by navigating to the
Storagetab at the top of the application page and pressProvision Storage. This may take anywhere for 3-5 minutes.
Configure API Keys
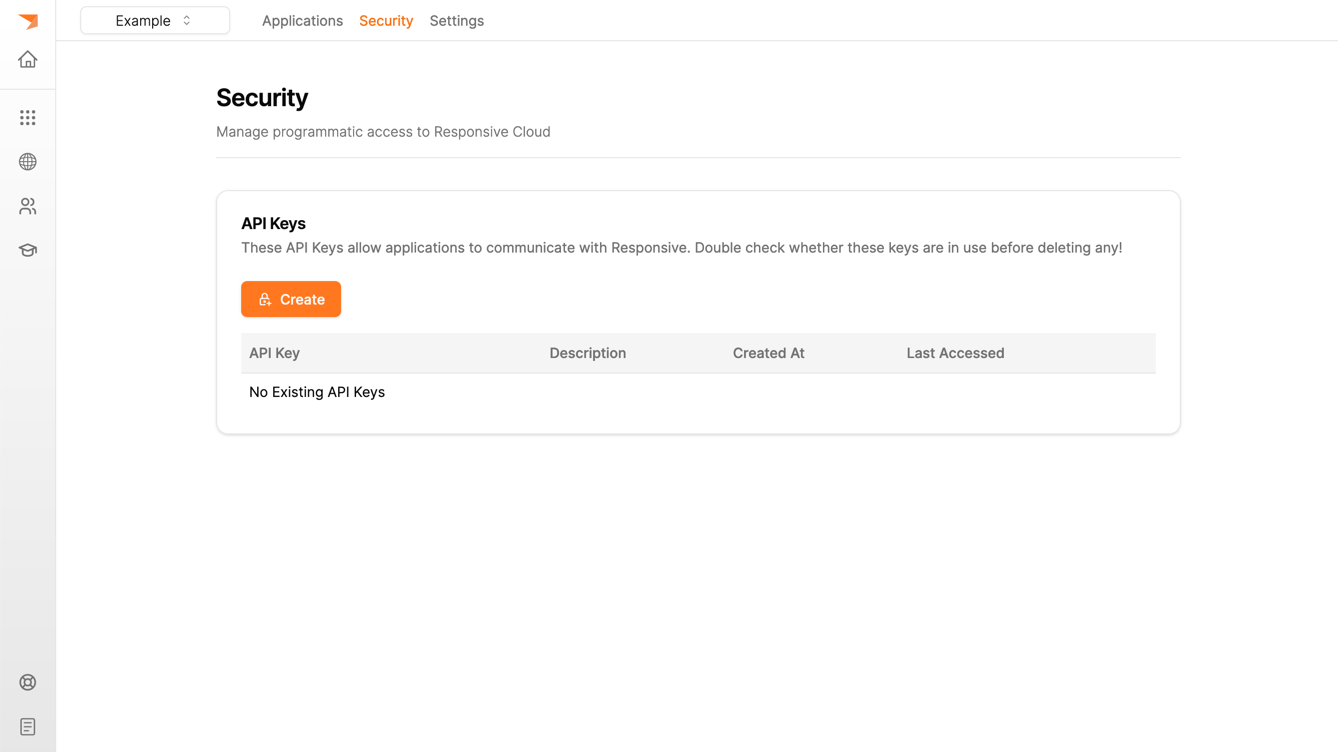
You will need API keys for metrics as well as data storage. You can create both in the Responsive Cloud UI.
- For the metrics API keys, navigate to the environment "Security" tab in the top navigation bar (or press the button to create an API Key in the Tutorial after setting the environment in the second step).
- To create the storage API keys, first wait for the provisioning to complete and then create your API keys. Since you are running this locally make sure to add your local ip to the access list. This happens within the scope of an application (so first select your newly crated application).
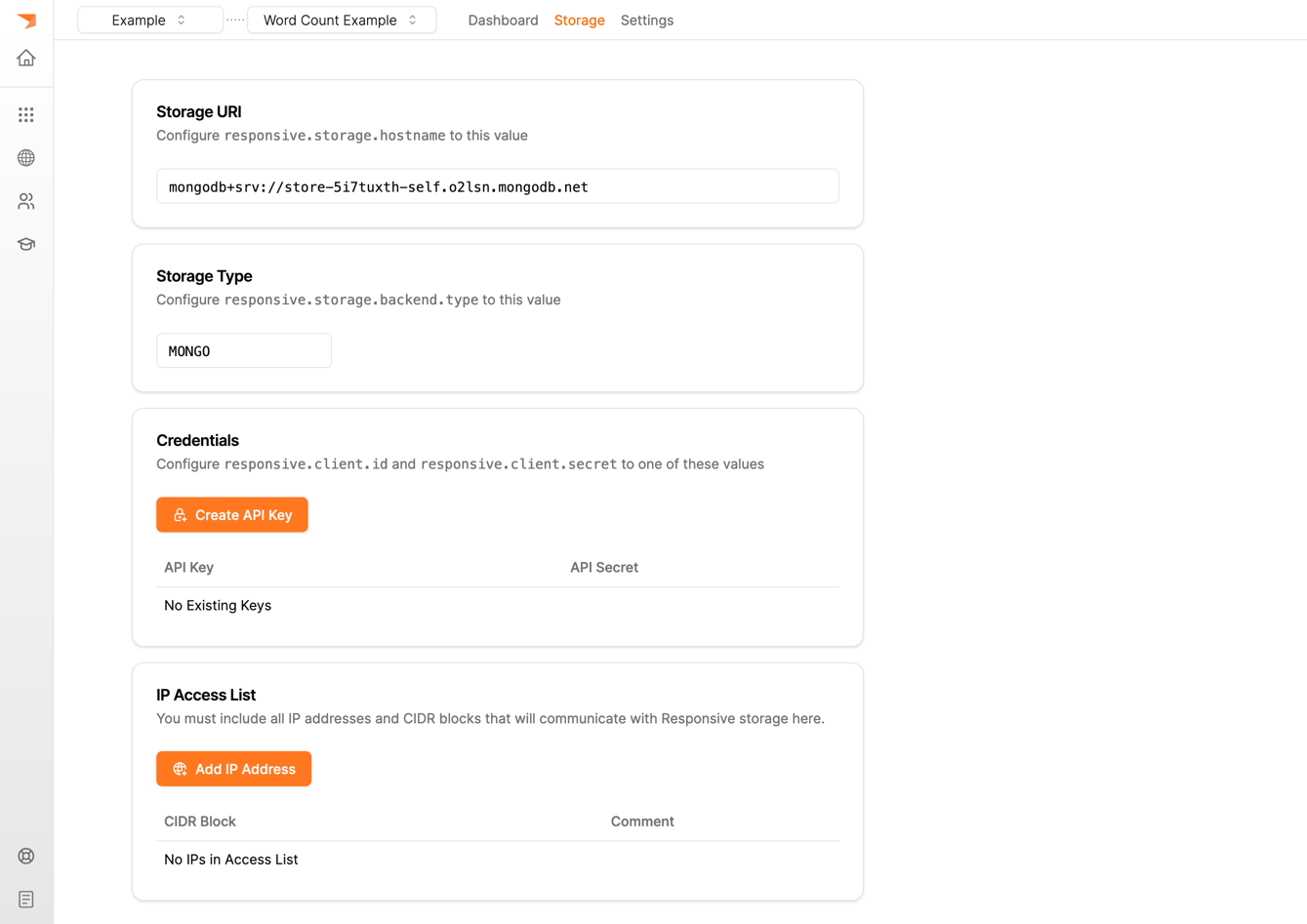
When you create these keys the UI will automatically download them on to your local disk. Note that you will need to change the contents of these files to match the expected configurations (we are working on improving this!)
Migrate to Responsive
Code
You may either follow the steps in the tutorial UI or apply the patch below to automatically make the required code changes.
git apply streams-app/src/main/resources/responsive-patch.diff
diff --git a/streams-app/src/main/java/dev/responsive/example/Main.java b/streams-app/src/main/java/dev/responsive/example/Main.java
index 8f8f627..6668c41 100644
--- a/streams-app/src/main/java/dev/responsive/example/Main.java
+++ b/streams-app/src/main/java/dev/responsive/example/Main.java
@@ -16,6 +16,8 @@
package dev.responsive.example;
+import dev.responsive.kafka.api.ResponsiveKafkaStreams;
+import dev.responsive.kafka.api.stores.ResponsiveStores;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
@@ -78,7 +80,7 @@ public class Main {
props.forEach((k, v) -> config.put((String) k, v));
final Topology topology = topology();
- final KafkaStreams streams = new KafkaStreams(topology, props);
+ final KafkaStreams streams = new ResponsiveKafkaStreams(topology, props);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
streams.close();
@@ -119,7 +121,7 @@ public class Main {
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
- .count(Materialized.as(Stores.persistentKeyValueStore("word-counts")));
+ .count(Materialized.as(ResponsiveStores.keyValueStore("word-counts")));
// Store the running counts as a changelog stream to the output topic.
wordCounts
Configs
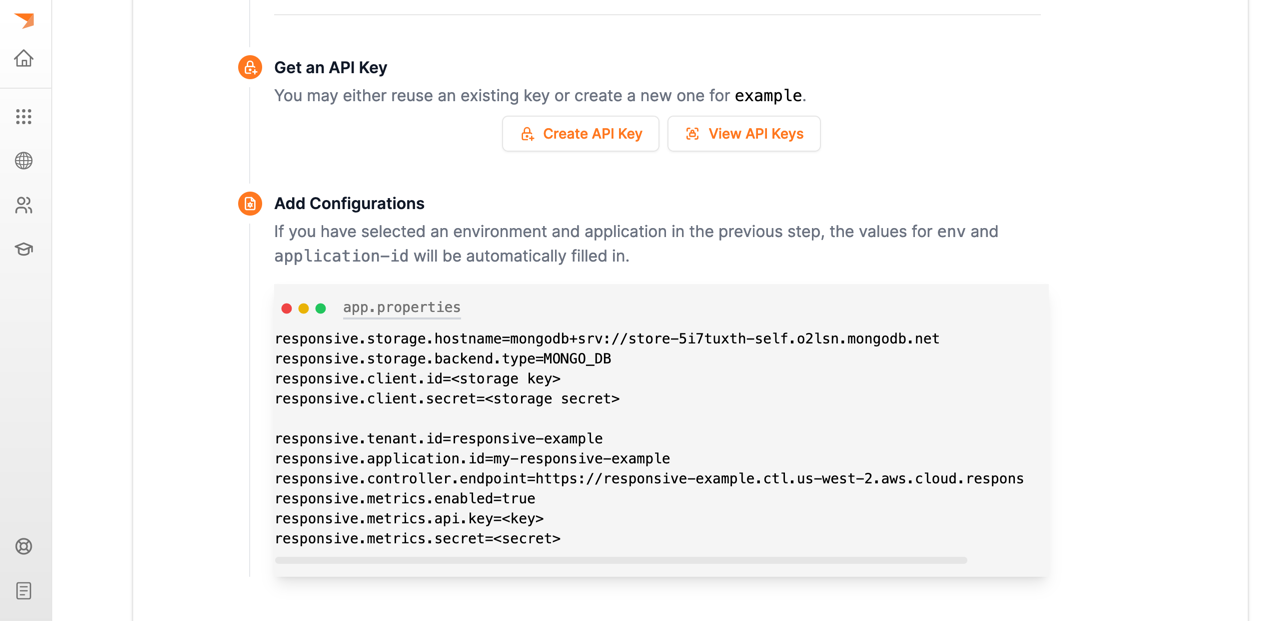
There are two parts to the configurations:
- the application configurations (the default is stored in
./kind/app.properties) - the API secret configurations for the keys you created previously
The application configurations should be filled out by copy-pasting the configurations displayed in the UI (omitting the secrets):
The secrets will be loaded from the ./secrets/responsive-creds.properties file using
Kubernetes Secrets. Make sure to update it to match the following:
# metrics secrets (environment API key)
responsive.metrics.api.key=
responsive.metrics.secret=
# storage secrets
responsive.client.id=
responsive.client.secret=
Rebuild & Redeploy
Now that you've migrated your code to use ResponsiveKafkaStreams and configured
the credentials, you can rebuild and redeploy your application using the same
commands:
./gradlew :streams-app:jibDockerBuild
bash ./kind/bootstrap.sh
If everything worked, you will see the processing metrics begin populating on the application dashboard. Note that some metrics are computed by the Responsive Controller, and will not be computed until you configure an autoscaling policy.
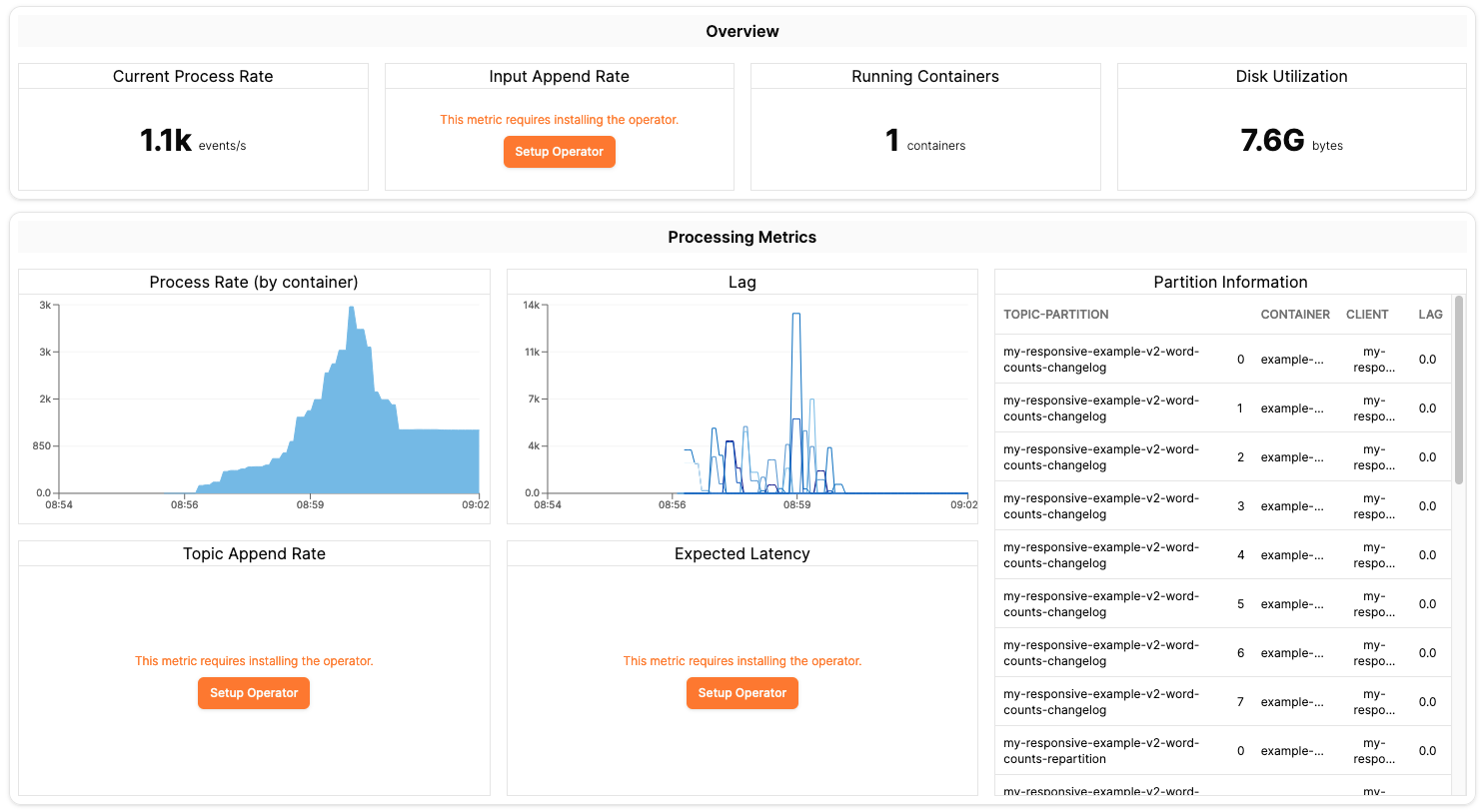
Configure Autoscaling
Navigate to the operator onboarding tab in the tutorial page and follow the instructions to set up operator. Once you have operator set up, you can configure the autoscaling policy:
kubectl apply -n responsive -f ./kind/policy.yaml
This will register my-responsive-example with the operator with a policy that indicates that
whenever a single node is processing more than 2000 events per second to scale out (up to three
nodes) and whenever all nodes are processing less than 1000 events per second to scale down. You
may configure the policy with whatever parameters you'd like to see how responsive handles the
modifications.
Once the controller successfully computes a window of data (you will need to wait about a minute) you will start seeing the full metrics appear on the dashboard:
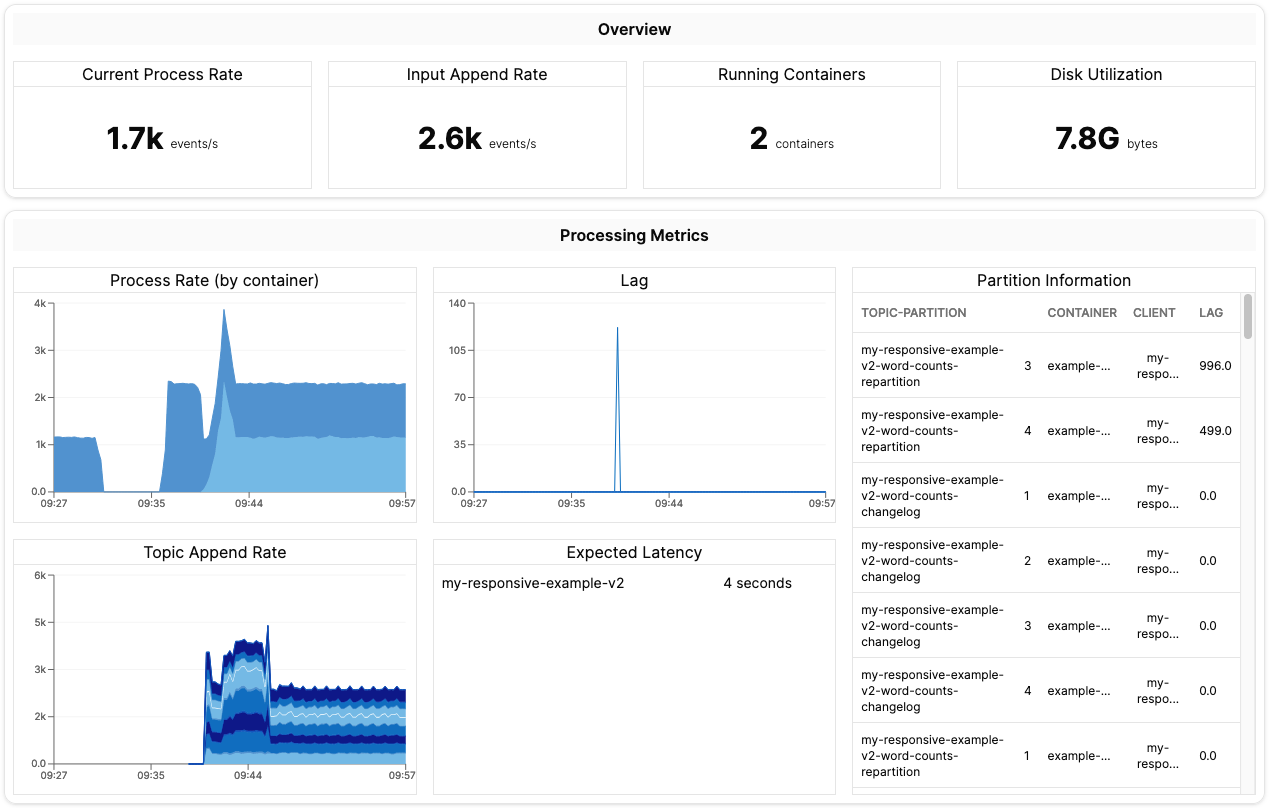
You may begin varying the event generation rate by scaling the generator deployment up or down:
kubectl scale deployment -n responsive generator --replicas <N>
Each replica of the generator will generate approximately 1100 events per second, so as you scale it up you will see the processing rate on the dashboard increase.
Troubleshooting
Metrics Not Displayed on Dashboard
There are generally two types of issues that may cause this problem:
- You configured a different
responsive.applicaiton.idin your Java app and in the Responsive UI - You have a misconfigured credentials
You can confirm the latter by checking the logs for the example deployment and look for
any errors (such as Invalid API Key or Secret).
kubectl logs -n responsive deployments/example
Seeing Invalid API Key or Secret in the Logs
Make sure that you have properly configured secrets/responsive-metrics-creds.properties file.
An example file looks like this:
# Responsive API Credentials | responsive-kind
responsive.metrics.api.key=ABCDEFGHIJKLMNOP
responsive.metrics.secret=ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFG1234567890=
...
Getting Exception opening socket When Connecting to Storage
Make sure that you have added your local public IP address to the whitelist in the Storage tab on https://cloud.responsive.dev.
Helm install command failing with 403
Make sure that your docker credentials are valid. If you have previously logged into the public ECR it is likely that your credentials have expired. You can just log out of ECR:
docker logout public.ecr.aws