RS3: Responsive Streaming Storage Service
The Responsive Streaming Storage Service (RS3) is a managed state store for Kafka Streams built to be object-store native with SlateDB. With RS3, you can enjoy all the benefits of managed state with far superior elasticity, and far lower costs, without sacrificing performance or correctness.
RS3 is Responsive's cloud native managed StateStore built on top of SlateDB.
It offers a superior cost and operations profile compared with other databases while delivering all the benefits
of disaggregated state. It's particularly relevant to applications with large amounts of state since it solves the
reliability and operability problems typically faced by these applications without adding significant costs.
This page covers the high level RS3 architecture and benefits, and has information for how you can sign up for the private beta of RS3.
RS3 Architecture
RS3's design principles
All implementations of the Kafka Streams StateStore interface ultimately need to satisfy these high-level
requirements:
- Support a high rate of updates, to enable high throughput workloads.
- Support fast key lookups, to enable fast aggregations.
- Support fast range lookups, to enable fast joins.
- Some sort of compare-and-set operation to align with Kafka transactions.
Embedded RocksDB satisfies those requirements, as do databases like MongoDB and ScyllaDB. However, embedding RocksDB has many drawbacks, and remote databases can get extremely expensive and also hard to operate at scale.
RS3 was built to enable remote state with low operational overhead and in an extremely cost-effective way. It achieves this goal by fully leveraging Kafka along with objectstores like S3 to solve the hardest problems that a database must solve:
- At one end, RS3 uses Kafka for a write-ahead-log (WAL) with isolated writes that serves as a durable, highly available, and transaction-aligned staging area for the most recently written data.
- On the other end, it relies on a cloud object store like S3 to provide cheap, durable, and highly available storage for the bulk of the store's data, and a channel to replicate data to caches at zero cost.
By using Kafka as a transactional write ahead log and S3 as a persistence and replication layer, RS3 can remain simple while benefiting from cloud economics.
How RS3 Works
RS3 itself is composed of a service and a client that plugs into Kafka Streams. Together, they materialize the WAL into a queryable store persisted in an Object Store.
Before digging in further, let’s define a few terms for those not as familiar with Kafka Streams internals:
- State Store: A State Store is a facility provided by Kafka Streams for storing and querying state for stateful operators like aggregations and joins. Kafka Streams provides interfaces for implementing custom state stores. RS3 leverages this to present itself as a State Store to Kafka Streams.
- Changelog Topic: Internally, Kafka Streams produces all writes to a State Store to a changelog topic. When running with exactly-once semantics (EOS), Kafka Streams produces the changelog as part of the same Kafka transaction as outputs and offset commits to ensure that state stores are written transactionally as well. RS3 uses the changelog topic as its WAL.
Now let’s look more closely at the RS3 storage service and client:
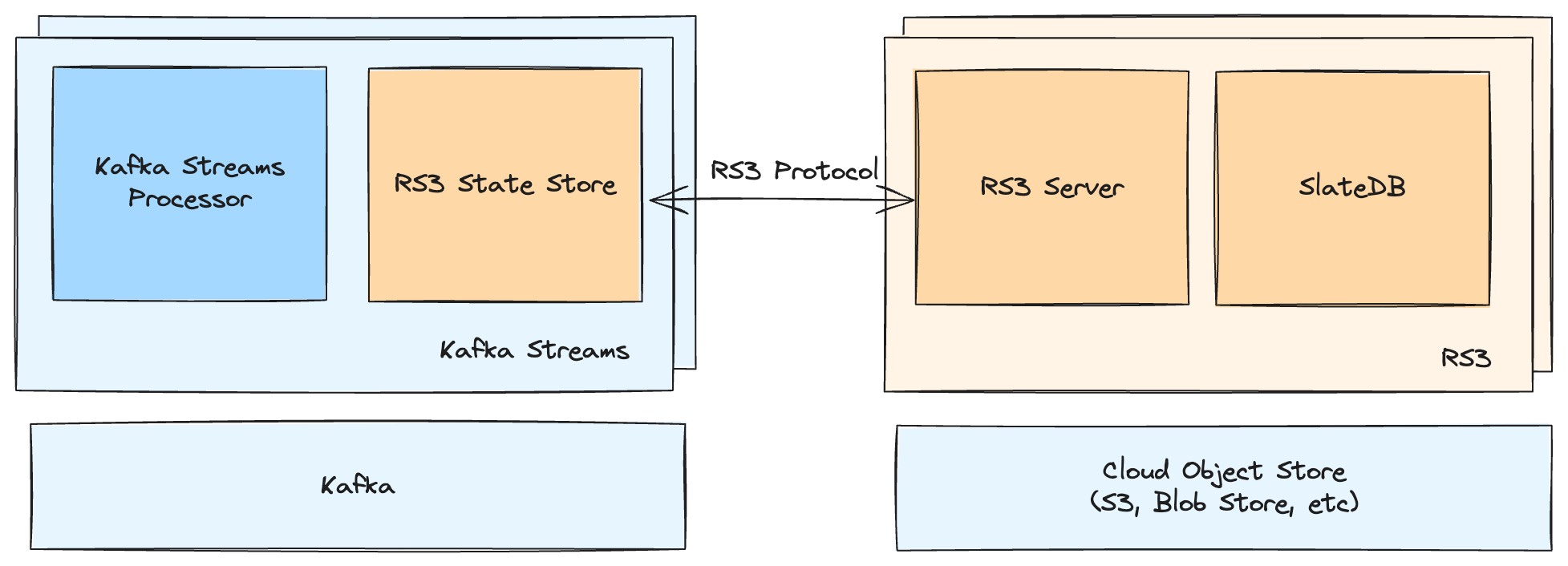
The RS3 service serves RS3’s GRPC protocol for writing segments of the Kafka changelog and querying the store. A segment is a subset of the changelog starting at a start offset and containing all data up to an end offset.
Each write request specifies the start and end offset of the contained segment. When handling writes, RS3 first verifies that it has all data up to the start offset of the segment. Then, it writes the data into SlateDB so that it can be efficiently read.
SlateDB provides a fast LSM tree that uses a cloud object store (like S3) for persistence, while caching the working set in memory and (optionally) on local disks. RS3 will also support maintaining replicas of the cache for high-availability and enabling placement of tasks in the same zone as the data being accessed.
Thus, the RS3 service leverages SlateDB to materialize the Kafka changelog into the object store while enabling fast key and range lookups. This is very similar to the way Kafka Streams uses RocksDB except that persistence is in S3 and the state is decoupled from your app, bringing significant operational and cost benefits.
SlateDB is an Apache 2.0 licensed LSM tree implementation designed for object stores. SlateDB has applied to be a part of the CommonHaus Foundation. Responsive has been one of the primary contributors to SlateDB from day 0, and we look forward to building SlateDB with contributors from across the industry!
We think a storage technology like SlateDB is a perfect way to bring cloud-native state storage to stream processors like Kafka Streams because LSM trees are a great fit for both streaming storage and object stores. They are designed to accommodate the high write rates of streaming workloads and are composed of large immutable objects, which make them well suited to the object store APIs.
Next, let’s zoom into the client, which runs in your application context and allows your Kafka Streams application to use the RS3 service:
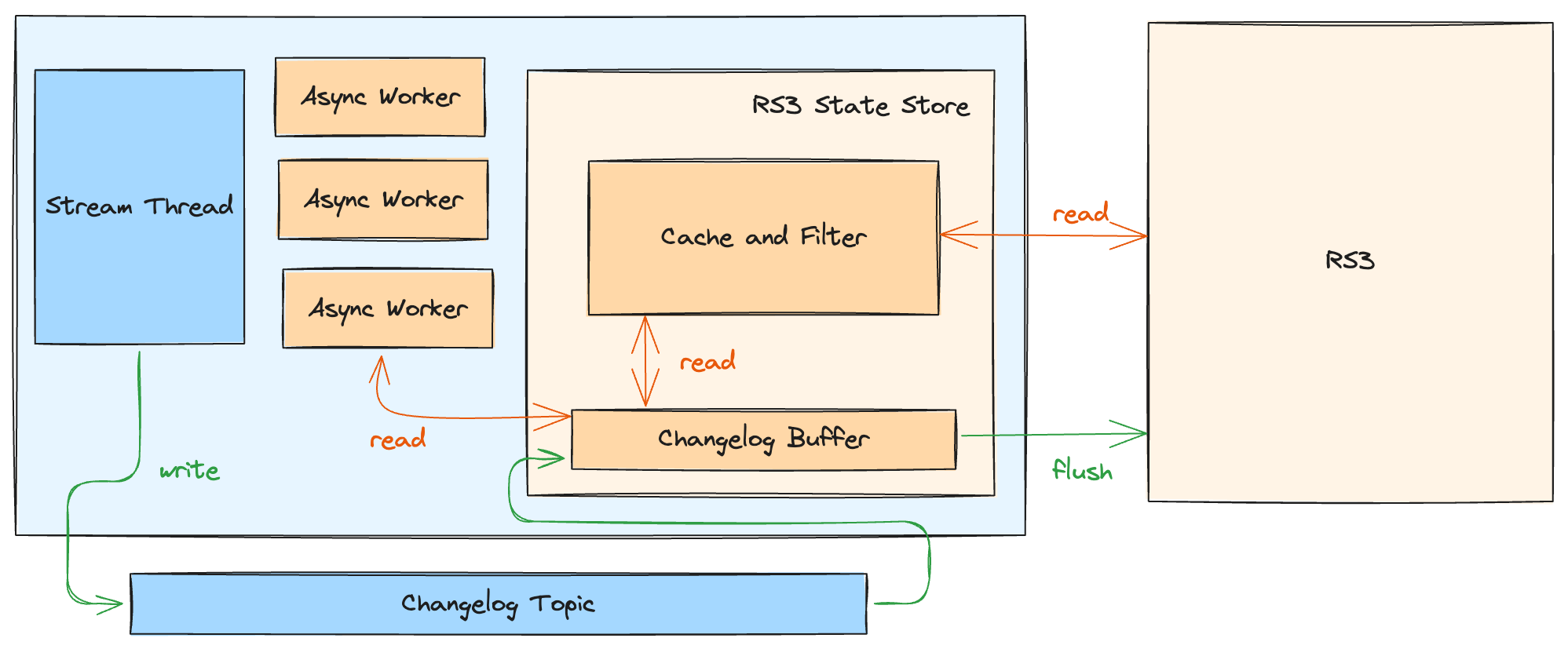
The client presents itself to your app as a Kafka Streams StateStore. It buffers the store's changelog topic, and
flushes the buffered data to RS3 using the RS3 protocol. Once data is flushed, it’s cleared from the buffer.
When Kafka Streams calls a state store read API, the client first looks in the local buffer. If the requested data is not present, it sends the read to the RS3 service. Additionally, Responsive makes some optimizations to mitigate the latency added by requesting remote data:
- The State Store maintains a cache so that recently accessed data can be served locally.
- For windowed operators, the State Store maintains a bloom filter of the keys in the current window to avoid remote lookups for the first key in a window.
- Responsive's async processing lets you add parallelism to a single stream thread to achieve high throughput in the presence of remote reads. You can use this in conjunction with RS3 to mitigate higher latencies from remote reads.
Observe that because the hard problems of building a distributed storage system are solved by S3 and Apache Kafka, what remains is lightweight and stateless. This makes RS3 easy to operate, even in a BYOC model.
Benefits of RS3 for Kafka Streams applications
10x cost reductions compared to other managed data stores
RS3 takes advantage of existing building blocks and the unique cost structure of the public cloud to provide streaming storage at a fraction of the cost of existing managed data stores.
What makes RS3 so much cheaper
Traditional storage systems maintain 3 replicas for high availability and durability.
This means running 3 times the compute and storing data 3 times on expensive, high-performance drives. RS3 on the other hand persistently stores data in object stores, which have per-GB storage costs that are a fraction of the cost of attached disks. The RS3 service itself just maintains an in-memory and optional on-disk cache of the working set. Further, the service can run with a single replica, with the option of adding standby capacity for fast failover. The RS3 service itself is stateless so the amount of standby capacity can vary from none to full warm replicas of caches.
Maintaining 3 replicas of data also means that the data must be transferred between the replicas of the data store, typically across zones, when writing the data store’s WAL. Inter-zone data transfers are notoriously expensive in the cloud. RS3 relies on the WAL that's already provided by Kafka and used with Kafka Streams today via changelog topics. So RS3 doesn't need to pay this duplicated replication cost. It does support the option of replicating caches for fast failover, but that process reads data from S3 rather than other RS3 nodes, which is free.
Taken together, these advantages allow RS3 to achieve up to a 10x reduction in cost compared to using a traditional managed database as a remote store for Kafka Streams.
Example
Let’s illustrate the cost reduction for a Kafka Streams application which deduplicates records in a topic based on the record key. We see these deduplicator applications time and again in the companies we work with, and so they make a great application pattern to examine.
To deduplicate the topic, the application materializes the topic contents as a table in RS3. It also looks up the key of each incoming record in the materialized table to decide whether or not to forward the record. Records with keys that already exist in the table are not forwarded.
We ran this Kafka Streams app against RS3 running on a single AWS m5.2xlarge node (8 cores, 32GB of memory) and were able to sustain 20K records/second while building up 2TB of unique keys.
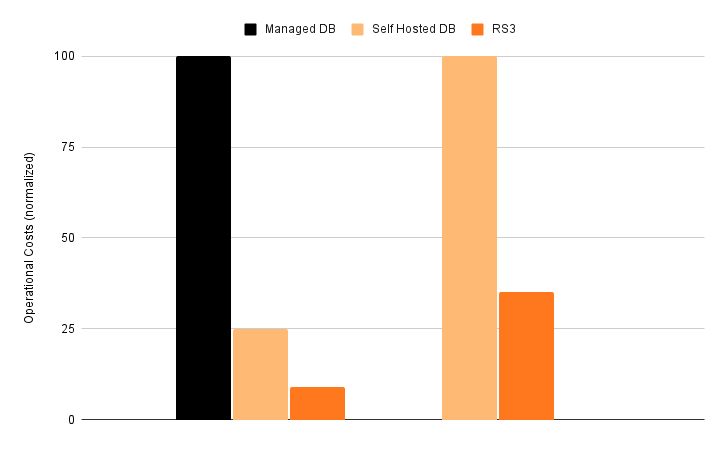
For the deduplicator application, RS3 is 92% cheaper to operate than a managed version of a popular open source database, and 66% cheaper to operate than a self managed version of the same open source database.
Flexibility
In this architecture, the storage nodes are nothing but caches on S3. This means:
- BYOC is practical: It’s much more practical to deliver a BYOC model with RS3 compared with traditional databases since the RS3 service that runs in the customer account is just a cache which doesn’t own any durable state. Needing to manage durable state is the biggest problem faced by traditional storage systems when they run in a BYOC model.
- Policy-based auto-tuning is possible: RS3 fits right into Responsive’s existing controller+operator architecture and leverages our existing observability pipeline to enable dynamic policy based autotuning for RS3. Since RS3 is a cache on S3, these tunings can be iterative while being minimally disruptive — no state has to move around to accommodate changes!
- Elasticity is natural: durable data doesn’t need to move around to scale up or down, making the system much more elastic than traditional storage systems.
Performance
Since the Responsive Kafka Streams StateStore implementation is already highly optimized to deliver high throughput
even with relatively high latency remote data stores thanks to async processing,
caching and bloom filters for windowed reads, and batching on writes, you can continue to get high throughput with the
Responsive Streaming Storage Service (RS3).