Understanding Origin Events
Origin events are the base usage unit for Responsive SDK. They are the first events that enter your streaming system and typically represent actions that are generated by real interactions within your business. This is in direct contrast to derived events, which are created when your applications filter, project, aggregate or join origin events.
The intention of billing on Origin Events is to allow developers freedom on how you design and build your Kafka application topologies. Responsive encourages splitting logic across many applications and sub-topologies instead of artificially clumping functionality into a single app.
Predicting Origin Event Volume
The easiest way to predict your origin event volume is to come up with a diagram that outlines how your stream processing architecture functions. Once you have this diagram, identify which topics contain origin events and compute the number of events processed by that application.
An example of such an architecture diagram is below:
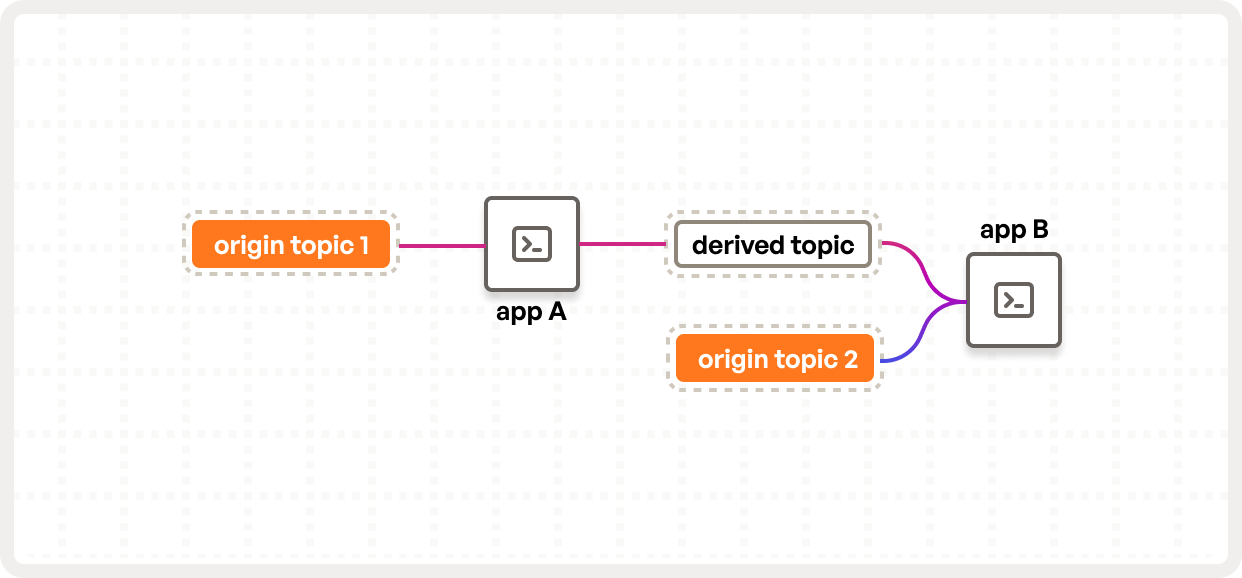
This sample architecture has two relevant components:
- There are two applications:
App_AandApp_B - There are three topics ingested by these applications:
origin_topic,derived_topicandorigin_topic_2.
You can imagine that App_A splits the input events from origin_topic, outputting 3 output events for every
input event and App_B then joins that output topic with a table represented with origin_topic_2. In this case,
all events in origin_topic and origin_topic_2 are origin events, while the data in derived_topic are all
derived events and would not count toward your origin event bill.
Once you have identified your origin event topics you need to figure out the monthly event volume on those topics. There are two ways of doing this:
- You can estimate by seeing your average process rate (JMX MBean
kafka.streams:type=stream-task-metrics,thread-id=[threadId],task-id=[taskId]metricprocess-rate) and multiplying that by the number of tasks and then by2,628,000(assuming 730 hours in a month) - You can estimate by looking at the offsets in your Kafka Topic, checking the offset number at the start of the hour and then again at the end of the hour, subtracting those two numbers and multiplying it by the number of partitions and then again by 730 (the number of hours in a month).
Note that both of these are estimates and may be off by a few events. The former does not account for re-processing and the latter does not account for transaction markers.
How Responsive Tracks Origin Events
Responsive requires that you run Kafka Streams with the ResponsiveKafkaStreams class. This class uses custom
producers and consumers for various reasons, one of which is to track and report origin events. Whenever an event
is produced by an application that uses the Responsive SDK, it will include a single byte header that indicates that
this event has been seen by Responsive. Whenever an event is consumed, the consumer checks for the presence of this
header. If the header is not there, it assumes that this is the first time this event has ever been seen by Responsive
and counts it as an origin event.
How Responsive Avoid Double Counting
Responsive makes sure that in any failure situations, we optimize for under-reporting the number of origin events. This is accomplished in a few ways:
- Responsive reports origin events only on commit, meaning if there is a crash and events are re-processed they will only count once.
- Responsive reports each origin event with a UUID, meaning any network blips that require retrying the request will be deduplicated once we process them in our system.
Mixing Responsive and Open Source
If you have some applications that use ResponsiveKafkaStreams and others that have not yet migrated, it is important
to note that the headers will be forwarded transparently by KafkaStreams as long as you do not modify them manually.
This means that any events downstream from a ResponsiveKafkaStreams application will contain the header, even if they
are later processed by vanilla OSS Kafka Streams applications.